
基于MacBERT-Transformer多模态 融合的上市企业财务造假识别研究
一、引言
随着金融市场快速发展和企业经营活动愈加复杂,传统财务风险检测方法难以满足现代监管与审计需求。近年来上市公司财务造假事件频发,扰乱市场秩序,损害投资者利益,也削弱了公众对财务信息真实性的信任。因此,如何识别并预警潜在舞弊行为,已成为监管与风险管理的核心问题[1]。
财务造假通常具有隐蔽性强、手段复杂和表象合理等特点,其线索多隐藏在财务报表附注、管理层讨论与分析(MD&A)及重大事项公告等文本中,同时也可能反映在财务指标的异常波动与盈余操纵行为中。有效整合并分析这些多源信息,是提升舞弊识别准确性的关键。
在此背景下,自然语言处理(NLP)[2] 凭借处理非结构化文本的优势,为造假识别提供了新路径。NLP融合计算语言学、机器学习和深度学习方法,能够自动提取语义特征、识别情绪倾向并捕捉异常表述[3]。随着BERT[4]、RoBERTa[5] 等预训练模型的发展,NLP在金融文本分析中的表现显著提升,已广泛应用于舆情监测、信用风险评估和审计异常识别。
在中文模型中,MacBERT(Masked Correction BERT)[6] 作为针对中文优化的BERT变体,在语义理解与上下文建模方面更具鲁棒性,通过改进掩码与建模策略,提高了对财务文本中语气、情绪及语义微差的识别能力。同时,Transformer模型[7] 在特征表达和序列建模中表现突出,适合处理文本与数值等多模态数据。
基于以上进展,本文构建融合MacBERT与Transformer的财务造假识别模型。模型首先利用MacBERT获取财务文本的深层语义特征,再与企业财务指标进行特征融合,并通过Transformer建模企业行为模式,实现对上市公司潜在造假行为的精准识别与风险预测。
二、NLP的基本概念与数据挖掘流程
自然语言处理(NLP)是人工智能的重要分支,旨在使计算机能够理解、分析并生成自然语言内容。其核心目标是将非结构化文本转换为结构化的数据表示,为自动化的信息提取、语义理解与风险识别提供支持。而NLP的整体流程通常包括三个关键环节:文本预处理、特征表示与建模分析。
首先,在文本预处理阶段,通过中文分词、去除噪声、停用词过滤、术语规范化等步骤,对原始文本进行清洗和标准化,为后续分析提供高质量输入。
其次,在特征表示阶段,将文本转化为可计算的数值向量。传统方法包括主要基于词频统计;而词向量嵌入(Word Embedding)方法可以捕捉更深层的语义关联与上下文依赖,使模型能够识别文本隐含的语义关系。
最后,在建模分析阶段,基于特征向量可构建多种机器学习或深度学习模型,包括朴素贝叶斯、支持向量机(SVM)、随机森林、循环神经网络(RNN)及 Transformer 等结构。其中,Transformer通过自注意力机制在长文本处理和语义建模方面表现尤为优异,因而被广泛应用于金融文本分析、风险识别与智能审计等领域。
三、财务文本与财务指标的特征构建
(一)文本数据预处理
文本数据预处理是构建基于NLP的财务舞弊检测模型的关键步骤,其质量直接影响后续特征提取与模型训练效果。由于上市公司财务报告、公告及新闻多为中文文本,且格式复杂、语义多样,建模前需对原始语料进行系统化清洗与规范化处理。
数据收集是预处理的起点,研究通常从年度报告、审计报告、管理层讨论与分析(MD&A)、上市公告及财经新闻等多渠道获取文本,这些非结构化数据需进一步处理才能提取有效信息。分词是中文文本处理中必不可少的环节。不同于英文的空格切分,中文需借助分词算法将连续字符划分为词语或短语。本文采用结巴(Jieba)等工具,以识别财务术语、专业名词和机构名称。
随后进行文本清洗,包括去除无关符号、HTML 标签和模板化表达,统一标点格式,并删除高频停用词,从而减少噪声、提升文本质量。接着开展文本规范化,通过词形还原和同义词归并,将表达不同但语义相同的词进行统一,如把“减少”“降低”“下降”归为同一类,以降低词汇稀疏性并增强语义一致性。
完成以上步骤后,文本进入特征提取阶段,将语言信息转换为模型可处理的数值特征。
(二)特征提取与表示
特征提取与表示是基于 NLP 的财务舞弊检测模型的核心环节,其目标是将预处理后的文本数据转化为机器学习算法可识别的数值特征,以揭示财务文本中潜在的舞弊信号与风险模式。早期方法中,词袋模型(Bag-of-Words, BoW)结构简单、易于实现,但由于忽略词序与上下文语义,难以捕捉隐含的欺诈意图或语气差异,应用范围较为有限。词频–逆文档频率模型(TF-IDF)通过衡量词语在文档与整体语料库中的重要程度,对“虚增”“重组”“亏损”“违规”等区分性强的词赋予更高权重,从而突出财务异常的关键信息。
在此基础上,本文采用词向量嵌入(Word Embedding)方法,在大规模财经语料上训练语义空间,使词语映射到低维连续向量中,语义相近的词在空间中距离更近。该方法能够有效捕捉上下文关系与语义细微差异,使模型能够识别如“规避责任”“提前确认收入”等隐含舞弊表达,相较于传统统计特征显著提升语义理解能力与泛化性能。
(三)模型构建与训练
在完成文本数据预处理与特征提取后,模型的构建与训练是实现上市公司财务造假识别的关键环节。整体思路是通过语义特征与财务特征的双通道融合,实现语言层面与数值层面的协同识别。
1. 模型架构设计
模型采用双通道结构:文本通道利用MacBERT提取财报的深层语义向量,财务通道输入企业关键指标,如资产负债率、现金流比率与应收账款增长率。两类特征归一化后拼接并输入Transformer模块进行分类,网络使用ReLU激活并通过Softmax输出造假概率。该结构同时捕捉文本异常表述与量化特征变化,实现多模态融合识别。
2. 预训练与微调机制
MacBERT基于大规模中文语料预训练,具备较强的语义理解能力。本文采用“预训练–微调”策略,先学习通用语言知识,再在年报、公告与财经新闻等领域语料上微调,从而增强对行业词汇与舞弊表达的识别能力,提高模型适应性与泛化效果。
3. 模型训练与优化
训练过程采用交叉熵损失与Adam优化器,并结合L2正则化与Dropout抑制过拟合。数据按 8:1:1 划分为训练集、验证集和测试集,用于参数学习、超参调优及最终评估,验证阶段加入早停提升训练稳定性。
4. 模型评估
模型性能通过准确率(Accuracy)、精确率(Precision)、召回率(Recall)与F1值(F1-Score)等指标综合评价,并辅以ROC曲线与混淆矩阵进行可视化分析。
四、实验设计与结果分析
(一)数据来源与样本构建
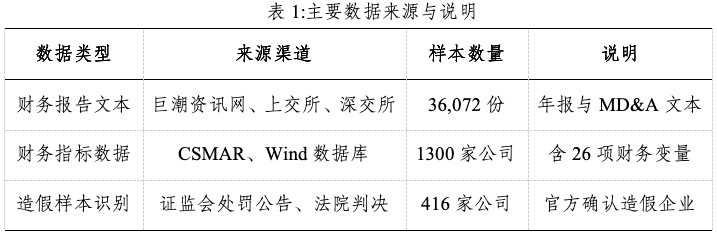
本研究以中国沪深A股上市公司为研究对象,选取 2015—2024年间经中国证监会处罚或被认定存在财务造假的公司作为造假样本,并从同行业、同规模企业中随机匹配非造假样本作为对照组。表1总结了主要数据来源与说明。其中数据主要包括两类:第一类是财务文本数据,其来源于巨潮资讯网及沪深交易所网站,涵盖上市公司年度报告和管理层讨论与分析部分;第二类是财务指标数据,其来源于CSMAR和Wind数据库,包含盈利能力、偿债能力、营运能力及成长性等26项核心指标。经清洗与筛选后,得到1300家样本公司,其中造假企业416家、非造假企业884家,对应约3.6万份财务文本。样本覆盖多数行业与不同年份,为模型训练与验证提供了坚实的数据基础。
(二)数据预处理与特征构建
为确保数据一致性与模型输入质量,本研究在建模前对样本数据进行了系统化预处理与特征构建。首先,对财务报告及公告文本进行去噪、停用词过滤和术语规范化,并使用 MacBERT-Base-Chinese 编码生成768维语义向量;随后通过平均池化获得公司层面的文本表示,并利用PCA将其降维至128维,以降低计算成本并保留主要语义信息。其次,对来自CSMAR与Wind的26项核心财务指标进行Z-score标准化,并对极端值进行1%分位截尾,以增强数据稳健性。鉴于造假样本占比较低,采用SMOTE对少数类过采样,使正负样本比例达到1:1,并将正常公司标注为0、被监管或司法认定造假的公司标注为1。最后,将降维后的文本向量Ti与财务指标向量Fi拼接,构建多模态输入矩阵[Ti ,Fi],起包含128维文本特征与26项财务指标,共154维,用于后续模型训练与分类任务。
(三)描述性统计分析
为验证样本数据的合理性及造假企业特征差异,本研究对主要财务指标和文本语义变量进行了描述性统计。分析维度涵盖盈利能力、偿债能力、现金流质量、盈余操纵倾向及文本披露特征等。其中财务指标包括净资产收益率(ROE)、资产负债率(LEV)、经营现金流比率(CFO_NI)、应计利润比(ACCRUAL)和收入增长率(GROWTH);文本变量包括管理层语气积极度(TONE)与信息披露一致性(DISC_CONS)。为检验造假与非造假企业差异的显著性,采用独立样本t检验,并在 1%、5%、10% 显著性水平下判断均值差异。
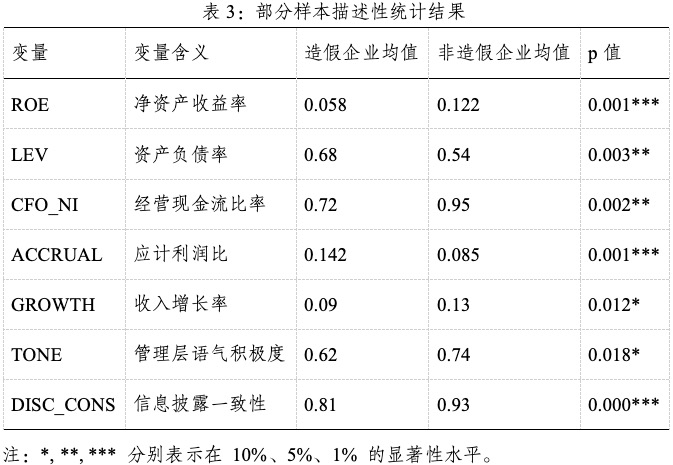
从表3可以推断出:造假企业的ROE明显低于非造假企业,表明其报告利润质量偏低;同时CFO_NI较低,反映其利润与现金流存在脱节。造假企业的 LEV 显著高于正常企业,说明其财务杠杆较高,可能通过虚增利润缓解偿债风险。较高的ACCRUAL值意味着造假企业存在更强的盈余操纵倾向,是财务舞弊的重要信号。造假企业的管理层语气积极度(TONE)显著较低,而信息披露一致性(DISC_CONS)差异更为显著,表明其报告内容前后不一致、信息透明度不足。总体而言,造假企业在多维度财务与文本特征上均与非造假企业存在显著差异,这为后续基于 NLP 与深度学习的财务舞弊识别模型提供了可靠的数据支撑与实证依据。
(四)模型训练与结果分析
1.模型结构与参数设置
将两类财务数据在特征级拼接成154维输入向量后送入Transformer模块。Transformer由4层编码器组成,每层含8个多头注意力头,隐藏层维度为256,激活函数为ReLU。分类部分由两层全连接网络(256→64→2)构成,并经Softmax输出造假概率。模型训练使用Adam优化器,学习率1×10⁻⁴,批量大小32,训练220轮,Dropout设置为0.3。
2.模型性能评估
为验证模型的有效性,本研究对比了多种主流分类算法,包括传统机器学习模型Logistic回归、支持向量机(SVM)、随机森林(Random Forest,RF)与深度学习模型LSTM、BiLSTM以及Transformer。模型在测试集上的性能结果如表4所示。
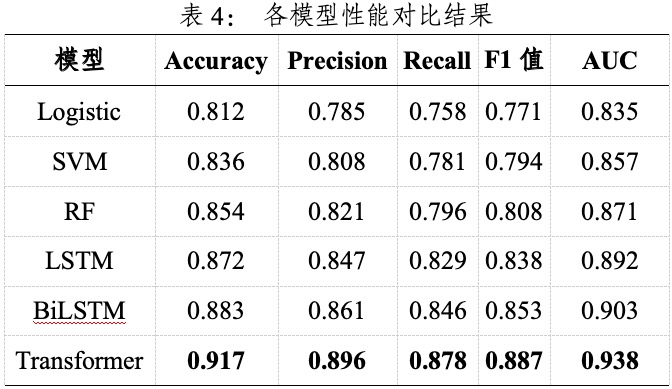
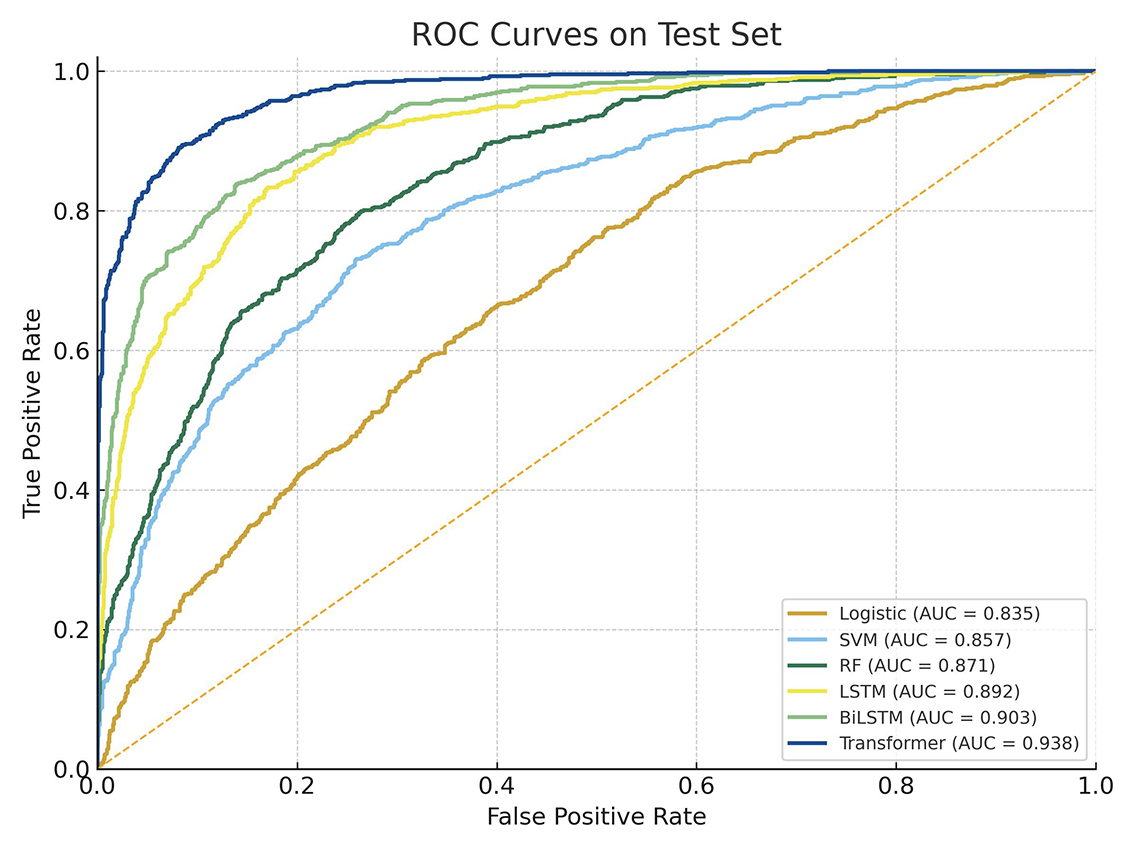
图1:各模型的ROC曲线
结果显示,MacBERT结合Transformer模型在各项指标上均优于传统模型与其他深度学习模型。其中,F1值与AUC分别达到0.887与0.938,表明该模型在识别上市公司财务造假方面具有较高的精确性与稳定性,图1所比较的各模型ROC曲线进一步支持这一结果。
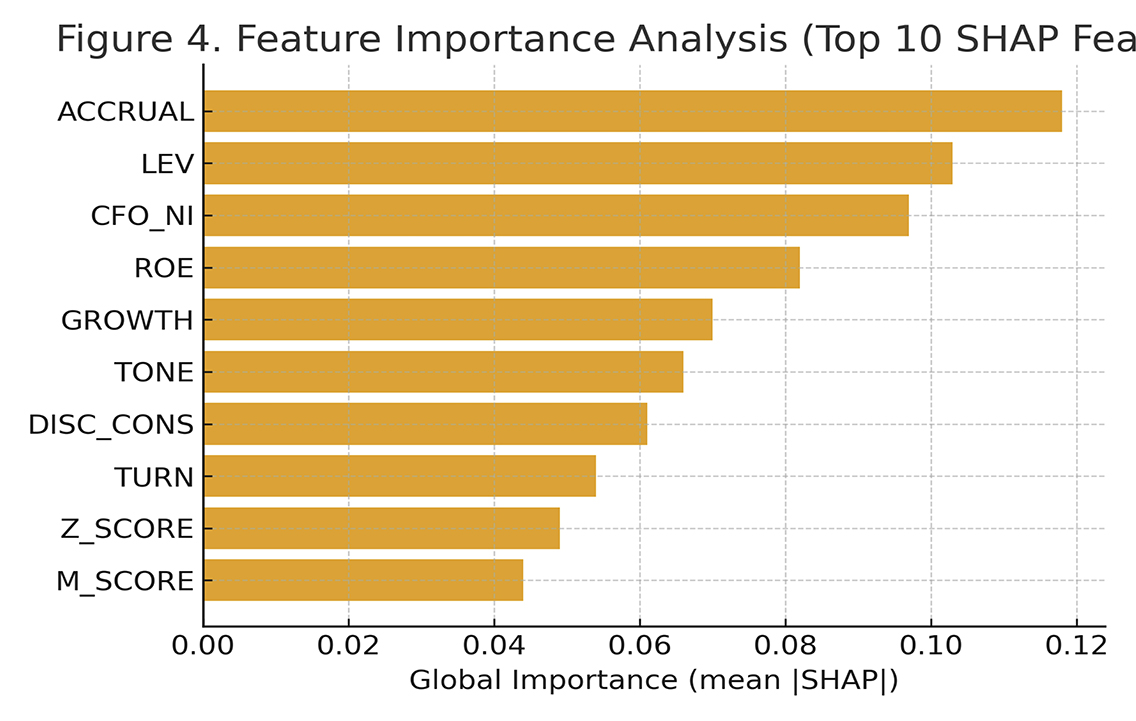
图2:前10个SHAP特征重要性分析
3.特征重要性分析
为增强模型的可解释性,接下来采用SHAP(SHapley Additive exPlanations)方法分析输入特征的重要性。图2展示了前10个关键特征的排序结果。可以看到,应计利润比(ACCRUAL)、资产负债率(LEV)和经营现金流比率(CFO_NI)的平均 SHAP 值最高,说明盈余操纵程度与杠杆水平对企业造假的预测影响最为显著。股东权益回报率(ROE)和增长率(GROWTH)亦具有较强解释力,表明盈利能力与扩张速度与舞弊动机密切相关。同时,信息披露一致性(DISC_CONS)和语气积极度(TONE)的重要性较高,说明管理层语言特征能够有效反映潜在风险。此外,资产周转率(TURN)、财务困境指数(Z_SCORE)与盈余操纵指数(M_SCORE)等指标也对预测结果有一定贡献,分别对应运营效率、财务稳健性与盈余管理风险,对识别高舞弊概率企业具有辅助作用。
总体来看,基于MacBERT-Transformer的多模态模型在财务舞弊识别中表现突出,不仅能捕捉文本中的隐含语义,还能综合反映企业财务结构与经营异常,为监管机构和投资者提供准确、高效且具可解释性的风险识别工具。
五、结论与展望
(一)研究结论
本文构建了MacBERT–Transformer多模态融合模型识别企业财务造假,将财务指标与管理层文本语义深度结合,实现结构化与非结构化信息的协同建模。模型对比结果显示,深度学习整体优于传统方法,其中MacBERT–Transformer在准确率、召回率和AUC上表现最佳,验证了语义与财务特征融合的有效性。该模型不仅能捕捉财务文本中的隐含舞弊信号,也能结合量化特征实现高精度识别。基于SHAP的特征重要性分析表明,应计利润比、资产负债率和经营现金流比率是影响舞弊概率的关键财务指标,而信息披露一致性和语气积极度等文本变量亦发挥重要作用。这说明管理层语言特征能够反映其风险态度与决策倾向,并与企业真实经营状况高度相关。
总体而言,多模态人工智能方法显著提升了财务舞弊识别的准确性与解释性,为监管机构和投资者提供了有效的数据驱动风险预警工具。未来研究可进一步引入时间序列语义建模与图神经网络,以增强模型的动态分析能力与可解释性。
(二)研究展望
尽管本文基于MacBERT–Transformer的多模态模型在财务造假识别中取得了良好效果,但仍有若干方向值得深入研究。
在数据方面,本文主要依赖年报文本和财务指标,未来可引入更丰富的数据源,如新闻报道、社交媒体舆情及审计意见等,以提升模型对潜在舞弊行为的捕捉能力。同时,可结合时间序列特征构建跨年度动态样本,更好反映企业财务与语言模式的长期变化。
在模型方面,可进一步优化多模态融合策略,例如采用跨模态注意力机制(Cross-modal Attention),更精准刻画财务变量与文本语义的关联;同时探索轻量化预训练模型与自适应微调(Adapter Tuning),提升模型在小样本环境下的可迁移性与训练效率。
在可解释性与应用层面,未来可结合因果推断方法,分析财务与文本特征对舞弊行为的作用路径,增强模型的经济学解释。同时,可将模型应用于企业审计、风险预警与监管场景,构建实时智能化风控工具,实现从研究到实践的转化。
此外,可进一步拓展至国际比较与跨行业研究,探讨不同制度环境、披露文化与监管强度下文本语义与造假行为的差异,为全球金融监管提供方法与经验借鉴。(西南证券股份有限公司博士后 张陈)
参考文献
[1]杨志国.上市公司财务造假机理与审计机构勤勉尽责的研究[J].财务研究,2025,(04):22-36.
[2]Zubiaga, Arkaitz. Natural language processing in the era of large language models. Frontiers in artificial intelligence 6 (2024): 1350306.
[3]Panchendrarajan, Rrubaa, and Arkaitz Zubiaga. Synergizing machine learning & symbolic methods: A survey on hybrid approaches to natural language processing. Expert Systems with Applications 251 (2024): 124097.
[4]Devlin, Jacob, et al. Bert: Pre-training of deep bidirectional transformers for language understanding. Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers). 2019.
[5]Liu, Yinhan, et al. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv: 1907.11692 (2019).
[6]Cui, Yiming, et al. "Revisiting pre-trained models for Chinese natural language processing." arXiv preprint arXiv:2004.13922 (2020).
[7]Vaswani, Ashish, et al. Attention is all you need. Advances in neural information processing systems 30 (2017).
CIS
















